What is Arabic Sign Language (ArSL)?
Arabic Sign Language or ArSL as it’s popularly called by its acronym, is a fascinating language and many people have started to see its value and purpose outside the Deaf community. It is a visual language formed by organized hand gestures, body movements, and facial expressions. Learning ArSL won’t just create meaningful relationships but will provide more job opportunities, as it’s becoming increasingly essential in many workplaces. Its growing popularity highlights the demand for non-verbal communication that enriches confidence in communicating with people in everyday scenarios. The ArSL alphabet (a.k.a fingerspelling) is one of the easier challenges when learning sign language and it’s a sign language basic necessary to know in order to succeed.
Note: ArSL uses only one hand to form the letters in the alphabet.
HERE’S THE ARABIC SIGN LANGUAGE ALPHABET TO HELP YOU GET STARTED IN LEARNING ArSL:

Any ArSL user knows how crucial being able to fingerspell and understand it in return truly is. Fingerspelling is used to spell out words that do not have a sign such as people’s names, countries, cities and brand names. When you’re in the early stages of learning and don’t know sign language phrases, the sign language alphabet can bridge the gap between you and the deaf person you need to communicate with.
Approach and Methodology
Dataset Overview
KArSL database for ArSL, consisting of 502 signs that cover 11 chapters of ArSL dictionary. Signs in KArSL database are performed by three professional signers, and each sign is repeated 50 times by each signer. The database is recorded using state-of-art multi-modal Microsoft Kinect V2.
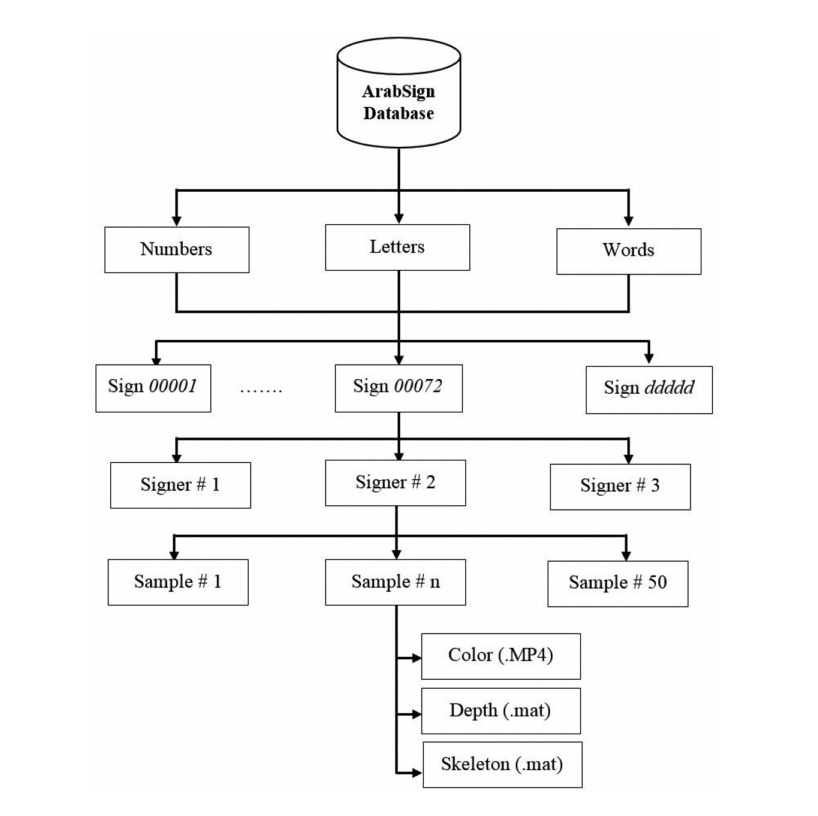
The hierarchical structure of KArSL database is shown below. The signs are categorized into three classes: (1) numbers, (2) letters, and (3) words. Each category contains a set of signs. Each sign is given a unique number of five digits. For each sign, there are 50 samples performed by each signer that are saved in MP4 file for color video and two binary files for depth and skeleton jointpoints. Each sign sample is saved with the name format: Category_Sign_Signer_ddddd_Type.ext where Category can be numbers, letters, or word; Sign is five-digit sign number; Signer is two-digit signer number; ddddd is a serial number of five digits; Type is the type of Kinect output: color, depth, or skeleton; and ext is the file type: color video (.MP4), depth and skeleton(.mat).
Note: We will use alphabet sub-dataset with only one hand in this part.
MediaPipe Framework
In June 2019, the developers at Google released MediaPipe into the open-source enviornment on GitHub. MediaPipe is a framework for building multimodal (eg. video, audio, any time series data), cross platform (i.e Android, iOS, web, edge devices) applied ML pipelines. With MediaPipe, a perception pipeline can be built as a graph of modular components, including, for instance, inference models (e.g., TensorFlow, TFLite) and media processing functions. More information is available in this review of MediaPipe.
![]()
Phases
When it comes to complete sign language translation, there are three main phases:
- Recognition of hands in motion, with some idea of hand persistence (left hand versus right hand).
- The translation of individual words.
- The interpretation of words into sentences (ArSL does not use the structured grammatical rules of Arabic).
Phase 1 is partially done by the hand tracking neural network provided by MediaPipe. MediaPipe can detect the presence and position of hands.
Phase 2 is given the coordinates from phase 1, output which character the user has signed. To completely finish phase 2 the neural network must be able to identify most words in ArSL.

MediaPipe Graph
I began the project by trying to break into the black box that was MediaPipe. While there is some basic documentation, much of what I learned was through experimentation and modification of the source code. After two weeks, I finally had a good idea of how to modify MediaPipe for my purposes.
![]()
The diagram above shows the MediaPipe graph for detecting and rendering the position of a hand in a video. MediaPipe works through a system of graphs, subgraphs, calculators, and packets.
-
Packets: Packets is simply any data structure with a time stamp. In the shown diagram,
input_videois the packet that is fed into the graph. TheHandLandmarksubgraph takes in the packets:NORM_RECTandIMAGEwhile outputs the packets:NORM_RECT,PRESENCE, andLANDMARKS. Packets are sent between calculators on each frame. -
Graph: A graph is the structure of the entire program. The entire diagram itself is a graph called “Hand Tracking CPU”. Graphs are defined in special
.pbtxtfiles and are read at the start of run-time, meaning that they can be modified without recompiling the code. -
Calculators: Calculators can have inputs and outputs. They run code on creation, per frame, and on close. An example of a calculator could be one that takes in coordinates of hands and outputs those coordinates being normalized. Another example of a calculator could be one that takes in a tensorflow session and a series of tensors and outputs detections. Some examples of calculators in the diagram are:
FlowLimiter,PreviousLoopback, andGate. -
Subgraph: A subgraph is a series of calculators grouped into a graph. Subgraphs have defined inputs and outputs and help to abstract what would be an otherwise over-complicated .pbtxt file and diagram. The subgraphs in the diagram are in blue and are:
HandLandmark,HandDetection, andRenderer. Read more about MediaPipe’s structure here
Summary
-
Real-time translation of sign language is a computationally difficult task that may not be possible on most consumer-grade hardware. However, new libraries such as MediaPipe are starting to make mobile real-time sign language translation possible.
-
One of the largest obstacles to the creating of a neural network for the translation of sign language is the lack of publicly available sign language data. Possible solution could be to crowdsource data collection.
-
The collection, management, and processing of training data is a task which cannot feasibly be done manually, and should be streamlined.
In the Upcoming articles we will talk about data cleaning and preprocessing, Extracting Holistic model positions/features for each frame of the videos and saving them locally to train our Deep learning model.